

An excellent code report efficiently evaluates the codebase's quality in terms of code cleanness, and identifies areas to be improved. It should also take special considerations about the reader since a report that's difficult to understand or too long, becomes a pain to read and is not useful.
This is why we approach our code reports with a top-down perspective, starting with higher-level descriptions of the system and eventually leading down to lower-level discussions at code level. We begin with a functional description of the system and provide a high-level explanation of its architecture to give context to the reader. Then comes a description of the design, stating why things are organized the way they are, with a brief discussion on tradeoffs that lead to it. Finally, critiques to code quality, considering best practices and principles follow.
This "top-down" approach is also known as the "newspaper metaphor" in Robert C. Martin's book: Clean Code. This book lays the foundation of our best practices guidelines and principles covering all the way, from design patterns, to how to name variables.
Now without further ado, we'll describe what we look for regarding the different aspects of a codebase.
Architecture
Even though the primary purpose of assessing the system's architecture is to give context to the reader of the code report, it can also be a great time to re-evaluate it given current business needs.
- Does the architecture support the most needed software quality attributes at the time? For example, in high growth times, it would be a good idea to have good scalability and extensibility.
- Is the architecture simple enough, or is it over-engineered? This can also be seen as the average time needed by a new developer to understand the current architecture.

Design
Like it happens with architecture, we mainly tackle design as an introduction to lower level aspects of the codebase. However, this also proves to be a perfect moment to evaluate the system's design on current business needs.
- Is there room for change in areas that may be subject to change in the future?
- How change within a particular portion of the codebase affects it?
- How hard is it to extend current functionality? Can it be done without modifying the existing code?
- Is it simple enough, or is it over-engineered? Can a new developer understand it relatively quick enough?
To evaluate this as well as the remaining aspects of the code, we rely on the Clean Code's SOLID principles:
- Single Responsibility Principle: every unit of code should have one and only one responsibility (it can also be thought of as having just one reason to change). This leads to more testable, readable, and maintainable code.
- Open Closed Principle: software entities should be open for extension but closed for modification. This allows for a piece of code to be extended (to have added functionality), without affecting existing code, which naturally leads to better extensibility of the codebase.
- Liskov Substitution Principle: a piece of code using a type high in an inheritance hierarchy should be able to support using a subtype within that hierarchy without altering desirable properties of that code (correctness, completeness, etc.). This one is especially suited for Object-Oriented designs as it helps evaluate whether a type hierarchy is correctly built and whether the code that it uses is generic enough.
- Interface Segregation Principle: no piece of code should depend on another piece that it does not use. This principle helps trim unnecessary dependencies.
- Dependency Inversion Principle: high-level entities should not depend upon lower-level entities; they should both depend upon abstractions. This intends to prevent implementation details that are subject to change in the future (thus impacting software) from guiding how software is made.
The Code Itself
Finally, we move on to the lowest level of our top-down approach: the code itself. Here we look at how different inherent attributes of the code affect its cleanness, and what do we mean by it.
For the following portion, all aspects are graded with an arbitrary scale -in our case a number from 1 to 10- coinciding with how much the codebase agrees with each criterion we define for each category.
We understand that the grading system has some subjectivity level. Still, we also believe that it is impossible to build an absolute grading system for software as there are many variables to be taken into account when grading.
Complexity
In terms of complexity, we seek the code to be simple enough to be read as prose, and its control flow is easy to follow. The more complexity there is, the harder the code is to read, and the higher probability there is of developers introducing bugs when trying to use or modify the code.
To evaluate complexity, we consider the following criteria:
- Can the code be read as prose?

- Do components follow the single responsibility principle?
- Do classes follow the single responsibility principle?
- Do functions follow the single responsibility principle?
- Is there a balance between the cohesiveness of code components and how decoupled they are from each other?
- Are SOLID principles considered in general?
- How extensible is the code? Is it extensible just where it needs to be?
- How maintainable is the code?
- Does the code follow the newspaper analogy from clean code? Are ideas introduced in a top-down manner, from a higher level of abstraction to a lower abstraction level?
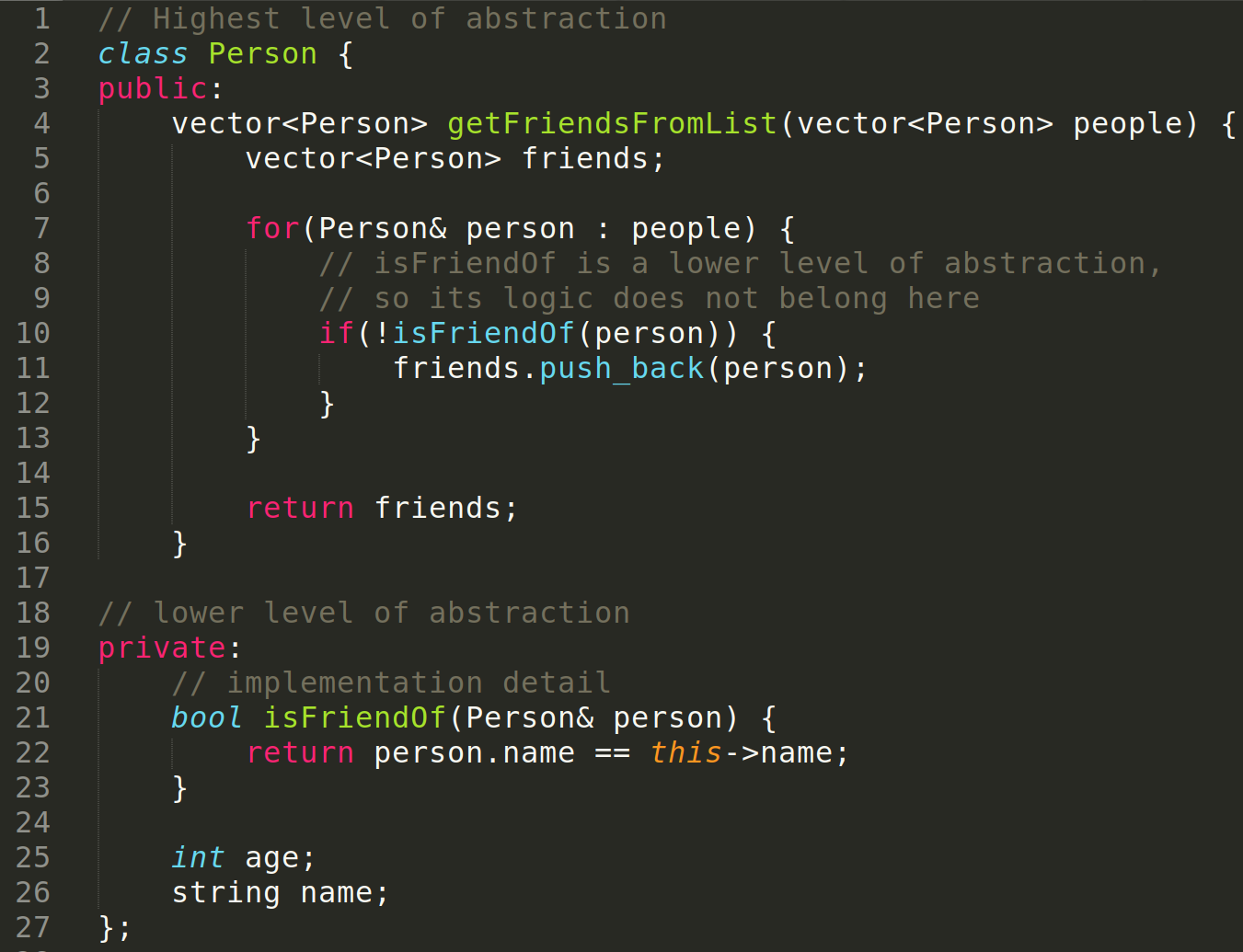
- Are levels of indentation kept to a minimum?
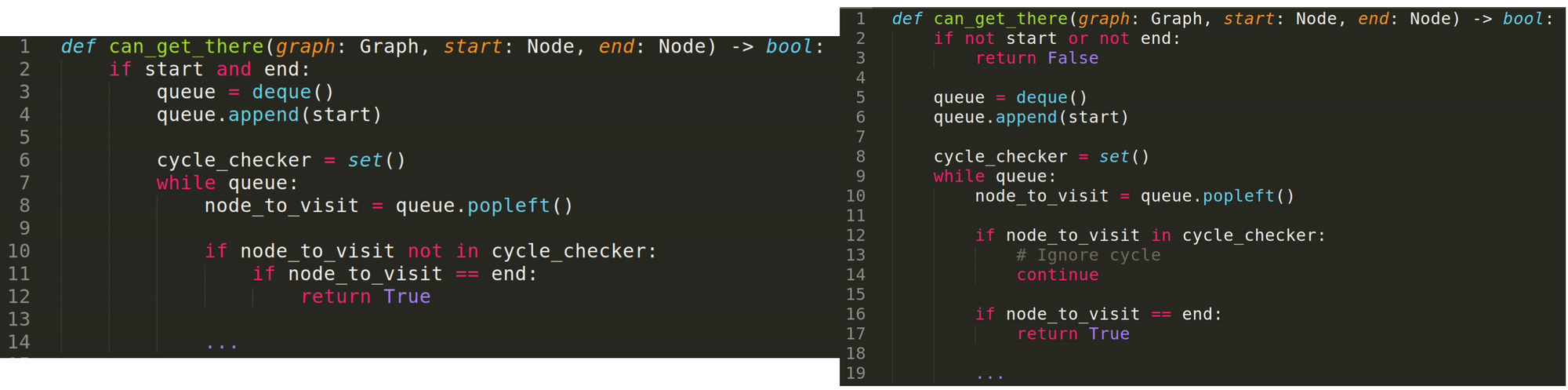
Automated Tests
Automated tests are essential as they provide implicit documentation of the system and give developers a sense of ease when making changes. This way, make sure that if something goes wrong with the changes, the tests will catch it. Nonetheless, this can be a false sense of security if tests are not appropriately made, and not to mention the fact that more tests translate into more code to be maintained.
To circumvent this, we consider the following criteria:
- Do all critical features have automated tests associated with them?
- Is there a balance between non-critical parts of the code being tested and the amount of extra code generated by tests that need to be maintained?
- Are there any unnecessary tests? We identify these as tests for 3rd party portions of the code that are already known to work or have tests of their own (e.g.: Google maps API), and trivial tests (e.g.: plain setters and getters).
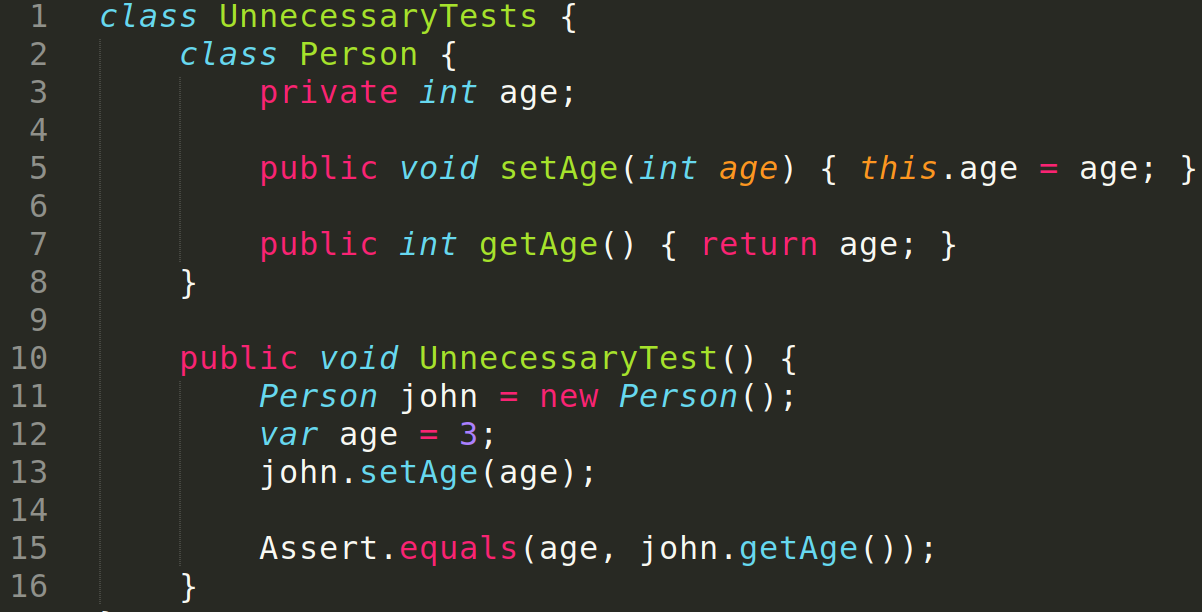
- Do existing tests clearly describe what they are testing?
- Do tests consider edge cases?
- Do tests follow the single responsibility principle? Do they test just one thing?
- Do tests consider just one level of abstraction?
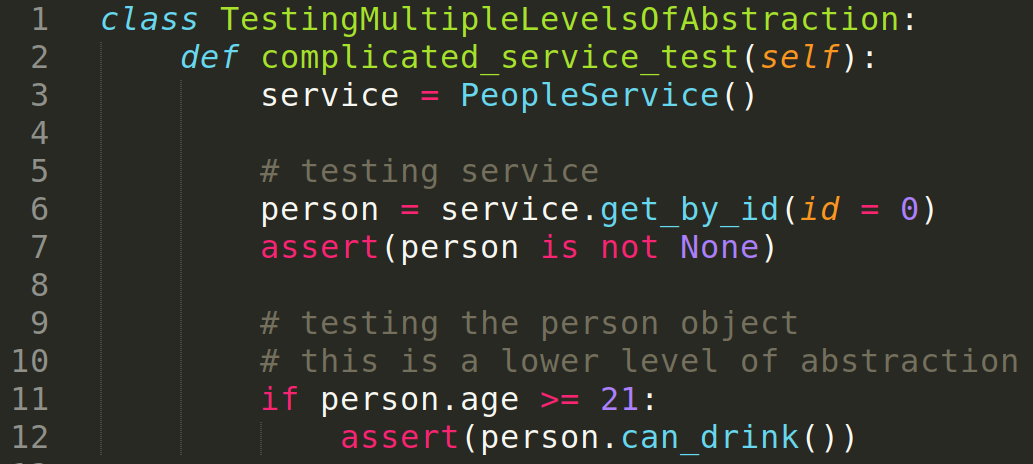
In the end, the idea is to strike a balance between the complexity that adding tests adds to the codebase and the probability of tests finding bugs.
Naming
Naming files, functions, and variables seems like an easy, mundane task, but it shouldn't go unattended. Great naming immensely benefits code readability, and consequently also affects many other quality attributes such as maintainability, testability, extensibility, etc. In general, we prefer longer descriptive names over shorter but harder to rapidly identify what that name refers to.
These are the criteria we follow when evaluating the naming of files, functions, variables, and classes:
- Do names describe what they reference logically? Are they intention-revealing?
- Do names avoid encodings? Are they pronounceable and searchable?
Comments
A common rule of thumb is that the code should be clear enough that no comments are needed, and that further comments regarding business logic or design decisions should reside in some kind of documentation. However, there are certain scenarios in which the inherent obscure logic or complexity of the problem makes it a necessity to have clarifying comments (or sometimes even comments explaining why that code exists).
Prioritizing clean self-explanatory code over comments is of paramount importance. Most of the time, comments are not updated at the same pace as code, which can turn an otherwise clean piece of code into a confusing mess.
- Can they be clearly read as "normal" spoken language?
- Are all written comments necessary, or can they be removed by having cleaner code?

- Are there any complex unexplained pieces of code?
- Are there lines of commented code? There shouldn't be any!
- Are there any lingering TODO comments that can be removed?
- Are there any outdated comments?
Style
When it comes to style, the most critical attribute we are looking for is consistency. There are many styling combinations and preferences, and all are equally valid but with a slight preference for the official styling guides, such as pep8 for Python. Where do we look for consistency:
- Pascal case, camel case, snake case on variable names, classes, instances, functions, packages, and every other nameable entity.

- Indentation with the same amount of spaces or tabs, exclusively.
- Opening braces on either on the same line or the next.
- Use of semicolons in languages where it is optional, such as Javascript.
Documentation
Even though documentation is not inherent to the code, it is a great practice to have some kind of it, possibly in the form of a README file, helping new developers to set themselves up to speed with minimal additional human help. What we look for:
- README files.
- API references.
- Environment files with explanations on what each variable is for.

Conclusion
The main objective is to evaluate the current state of the codebase in terms of code cleanness and identify areas that should be improved while doing it so the reader quickly understands what's going on and can come back and measure the improvement as quantitatively as possible.
To summarize, Light-it achieves this objective by sticking to a top-down approach when writing code reports. Starting from higher levels of abstraction that aim to give context and prepare the reader for what follows, all the way down to the lowest level where the code stands and the actual critique of it exists. Within that level, we identify several categories and criteria to rank the codebase in those categories.
This kind of reports help us minimize technical debt and maintain the "agility" of our company, allowing us to adapt to changes with the minimum cost possible, while also bringing the most value to our customers.